Things are getting busy at home, so I will be continuing the HP-67 emulator series in the new year. Enjoy your holidays.
Monthly Archives: December 2014
The HP-67 emulator, display program memory in the Curses CLI
Next, we want to make programming mode useable. It should display the program memory when we’re in programming mode, not the stack and memory registers. It will also display more valid keys, but that code was already in place, it just happened automatically when we entered programming mode.
The HP-67 calculator doesn’t have a key to press to enter programming mode. Instead, it has a slider that switches between interactive and programming modes. The Curses CLI needs a key definition for this operation, as anything the user can do will be through logical keypresses. So, we’ve defined a key for that, with a location that is not part of the normal calculator keypad. You’ll note that we haven’t actually defined a key yet for the reverse operation, but we will get to that soon.
With the latest changes, keypresses entered in program mode are stored into program memory, and not executed. They are then available for display in the UI. Here is a screenshot of this behaviour:
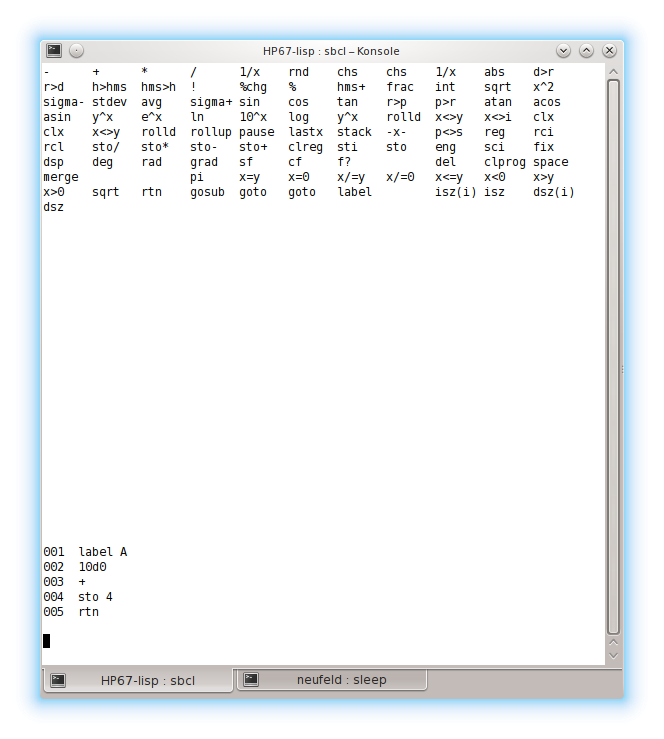
This is a program that, when “gosub A” is executed, adds 10 to X and stores the result in memory register 4. It then returns to the calling context.
The current version of the code can be found in the git repository under the tag v2014-12-14.
The HP-67 emulator, starting on program memory
The latest changes in the git repository, under tag v2014-12-10, allow the keypress handler to store keypresses in program memory rather than execute the forms. Code to store and retrieve program steps is now present in the stack module, and the UI handler passes program memory information to the UI for rendering.
One change in behaviour between the physical calculator and the way we’ve implemented programming here is in the handling of multi-keypress numeric constants, such as “12.3”. In the calculator, that number would require 4 program steps to record entirely, one for each character. In the keypress-handling engine, we’ve decided not to pass numbers into the program memory until they have been completed. This is because that arguably makes the program easier to read, and because some UIs can hand in entire numbers, which means that having “1” then “2” as sequential program steps might be interpreted as either the sequence “1” “ENTER” “2”, or the number “12”. To avoid this ambiguity, we declare that all numbers in a program step represent entire, not partial, numbers.
We still have a few more things to do before programming is ready. The ncurses CLI that we’ve written doesn’t actually display program steps yet, that will come soon. We also have to start paying attention to the return codes from keypresses because they will allow us to move the program counter around if the user presses “GOTO”, among other things.
The HP-67 emulator, and the rope data structure
The HP-67 calculator allows the user to enter program steps. These program steps need not be appended to the existing steps, they can be inserted in the middle of a previously-entered sequence. These steps have an associated index, their position in the program space, so if a new step is inserted at the beginning, then all steps after it must have their index incremented.
One could do this in an array, but insertions have a high cost as all the higher elements have to be shifted. One could use a list, but then random access is expensive because it’s not indexed. The natural way to solve this problem is with ropes. You can read more about the rope data structure on the Wikipedia page here (but note that, at the time of this posting, the Wikipedia text incorrectly asserted that some operations described required balanced trees, there is no such requirement).
A rope data structure is essentially a tree, the leaves of which contain the subsequences, in order. Insertion of new elements is done by cutting the tree at the insertion point, after which the insertion is just an append, which is relatively inexpensive. Afterwards, the cut trees are reassembled.
The code I’ve written for ropes is in a new file, ropes.lisp, in the git repository at the tag v2014-12-08.
You’ll notice in the code that there is a node structure and a rope structure, and that the rope structure contains only a single node. You might think that it would be more efficient simply to pass around the root node as if it were a rope, and avoid creating a second structure, but there’s a good reason for doing it this way. The operations that we are performing can modify the tree, and they can result in a rope that has a different root node. If the user passed in the node, rather than the rope, modification of that node would require more care, and some copying, to make sure that the user’s handle remained valid. By wrapping the node in a new structure, the rope manipulation code can modify even the root node without affecting the handle that the user passed.
Here are some sample pieces of code from the file. See the git repository for the full code:
(defstruct (node) (weight 0) (parent nil) (left-child nil) (right-child nil) (contents (make-array 0 :adjustable t))) (defun right-uncle (node) "Returns the node that is the first right child of a parent that doesn't return to myself, or nil if there isn't one." (when (node-parent node) (cond ((eq node (node-left-child (node-parent node))) (node-right-child (node-parent node))) (t (right-uncle (node-parent node)))))) (defun leftmost-leaf (node) "Returns the leftmost leaf under the node. Could be self, if there are no children." (let ((nlc (node-left-child node)) (nrc (node-right-child node))) (cond ((and (not nlc) (not nrc)) node) ((not nlc) (leftmost-leaf nrc)) (t (leftmost-leaf nlc))))) (defmacro iterate-over-contents ((rope obj) &body body) (let ((cur-node (gensym)) (cur-pos (gensym))) `(let ((,cur-node (leftmost-leaf (rope-root-node ,rope))) (,cur-pos 0)) (do () (nil) (cond ((>= ,cur-pos (node-weight ,cur-node)) (let ((uncle (right-uncle ,cur-node))) (unless uncle (return)) (setf ,cur-node (leftmost-leaf uncle)) (setf ,cur-pos 0))) (t (let ((,obj (aref (node-contents ,cur-node) ,cur-pos))) (incf ,cur-pos) ,@body))))))) (defun get-full-contents (rope) (let ((rval (make-array (rope-length rope))) (pos 0)) (iterate-over-contents (rope entry) (setf (aref rval pos) entry) (incf pos)) rval))
The HP-67 emulator, callbacks to obtain arguments
The new HP67-UI interface needs a way for the engine to call back to the user interface and request an additional argument when one is required. For instance, the memory-store key, STO, requires an argument to indicate where the store is to take place. If no such argument is supplied, it will be requested through this interface.
We used to ask the UI to build the appropriate query string, but it makes more sense to put this into the engine. So now, all the UI has to do is to write out the string it receives, without any modification or augmentation.
The handle-one-keypress function in the engine is not aware of the new HP67-UI interface. It doesn’t have to be, all of the method functions it might need to use are passed down to it inside closures. This is a very nice feature of Lisp, the ability to build closures easily and pass them down to functions. In C, you would do this with function pointers, but that requires writing the code in a separate function, which makes it less easy to see immediately what it is doing. The Lisp code in question looks like this:
(handle-one-keypress response
#'(lambda (x)
(hp67-ui:ui-get-argument ui x))
nil stack mode
:arg-is-num t))
This code is checked into the git repository under the tag v2014-12-06.