The index to the articles in this series is found here.
So, earlier we discussed thinning the uninteresting cases from the input set. Clear skies leading to no rain. We thought we’d like to cut the no-rain entries from the training set by about half, so that the resulting data set would have roughly equal numbers of training elements that showed no rain in the next five hours and elements that showed at least some rain in the next five hours.
We proposed cutting those training elements that had the least summed intensity of rainfall over the six-image historical sequence, and discussed the danger of cutting an entire swath this way. The compromise I’ve decided to use is to thin the low end by keeping only every sixth training member from the no-rain set, sorted from lowest total intensity to highest, until we reach our target amount of thinning.
Before we do that, though, it’s a good idea to try to understand what we’re throwing away. So, we compute the sum of intensities for all of those candidate training elements that show no rain in the next five hours, and order them. This allows us to produce a quick plot of summed intensity against number of training elements no higher than that. Here is that plot:
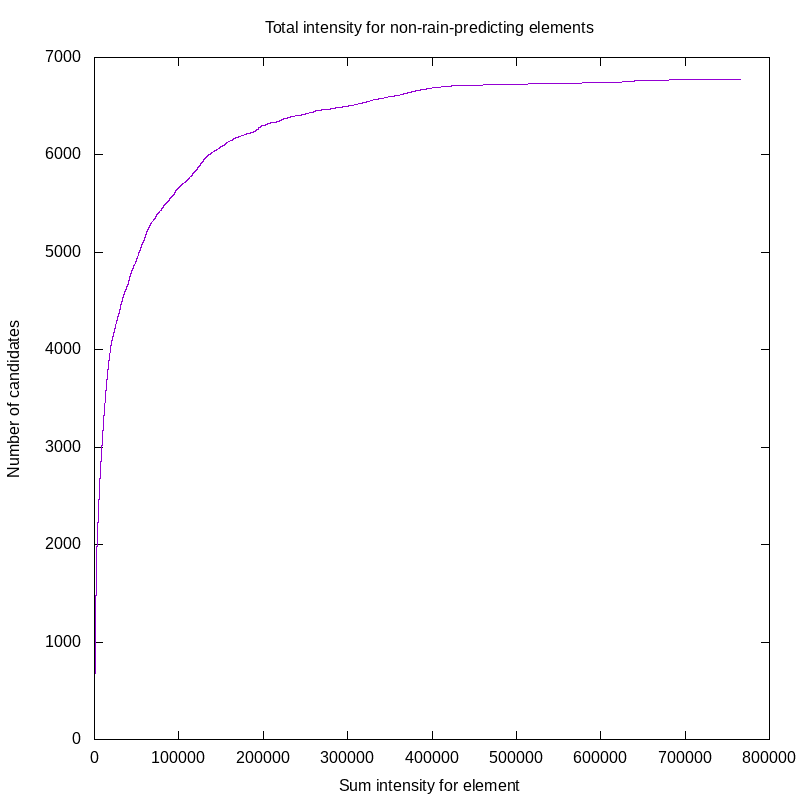
What we can see here is that we have under 7000 candidates that produce no rain at all in the five hours after the historical window. In the first 4000 such candidates, the total rain intensity comes in with a low summed intensity. In fact, the 4000’th candidate has a summed intensity of 18833. This compares to almost 800000 on the high end. So, our candidates that produce no rain are quite heavily skewed on the side of very low intensities. This is helpful, it indicates that we can preferentially drop those low-sum-intensity entries from the candidates list without adversely affecting our training data.
Good, so we’ve checked that, and this vetoing is reasonable. Here’s the code to produce the veto list (and also to produce the data for the plot above). make-vetoes.py:
#! /usr/bin/python3
# Before we go off cutting out candidates from the training set, we
# should make sure we understand the data we're eliminating. So,
# we'll generate a data set that can be used to plot candidate rain
# intensity on the Y axis and number of training candidates with
# values at or below that sum on the X axis
import argparse
import rpreddtypes
import sys
parser = argparse.ArgumentParser(description='Generate '
'intensity data for plotting.')
parser.add_argument('--candidates', type=str,
dest='candidates',
help='A file of candidates data from '
'get-training-set.py')
parser.add_argument('--sequences', type=str,
dest='sequences',
help='A file of sequence information from '
'prepare-true-vals.py')
parser.add_argument('--with-plotting-data', type=bool,
dest='plotdat', default=True,
help='Whether to generate plotting data '
'on stdout')
parser.add_argument('--veto-fraction', type=float,
dest='vetofrac', default=0.5,
help='Fraction of no-rain candidates to put in '
'the veto list for exclusion.')
parser.add_argument('--veto-keepstride', type=int,
dest='keepstride', default=6,
help='When writing vetoes, will exclude each '
'Nth entry from the list to ensure we don\'t '
'produce data that\'s too lopsided.')
parser.add_argument('--write-vetoes', type=str,
dest='vetofile',
help='If set, writes an unsorted list of '
'candidate sequence '
'numbers to skip because of common-case thinning.')
args = parser.parse_args()
if not args.candidates:
print('A file with the list of candidates must be supplied with the '
'--candidates argument')
sys.exit(1)
if not args.sequences:
print('A file with the list of sequence data be supplied with the '
'--sequences argument')
sys.exit(1)
seqIntensity = {}
sumIntensities = []
with open(args.sequences, 'r') as ifile:
for record in ifile:
fields = record.split()
seqno = int(fields[0])
pathname = fields[1]
reader = rpreddtypes.RpBinReader()
reader.readHeader(pathname)
seqIntensity[seqno] = reader.getTotalRain()
with open(args.candidates, 'r') as ifile:
for record in ifile:
fields = record.split()
startval = int(fields[0])
skipEntry = False
for i in range(4,14):
if (fields[i] != '0'):
skipEntry = True
break
if skipEntry:
continue
sum = 0
for i in range(6):
sum += seqIntensity[startval + i]
sumIntensities.append([sum, startval])
sumIntensities.sort()
if args.plotdat:
for i in range(len(sumIntensities)):
print (sumIntensities[i][0], i)
if args.vetofile:
recordsToDiscard = int(len(sumIntensities) * args.vetofrac)
with open(args.vetofile, 'w') as ofile:
for i in range(len(sumIntensities)):
if recordsToDiscard > 0:
if i % args.keepstride != 0:
ofile.write('{}\n'.format(sumIntensities[i][1]))
recordsToDiscard -= 1
else:
break
And there we are. We can now start developing our neural network, which will happen over the following posts.
It’s worth pointing out that, up to now, we have not discarded any information. Our training candidates use the full resolution of the original .gif files, and we have a veto list that can be applied to skip some if we choose, but so far we have preserved all the data we started with.
UPDATE #1 (2019-08-23): Included a link to an index of articles in this series.