The index to the articles in this series is found here.
In the last message, we talked about looking at the total weight of rain pixels in a training entry, since ones with a low total weight are less interesting to us. I decided that this total weight was something that would be useful to have in the header of the intermediate binary file. So, I’ve bumped the version number of that file, and made appropriate adjustments. At this point, I figured it might get confusing to follow along as I make edits to source code, so I’ve set up a github repository for the python files I’ve been writing here. You can find it at: https://github.com/ChristopherNeufeld/rain-predictor
I’ll update the first post to mention the github source.
UPDATE #1 (2019-08-23): Included a link to an index of articles in this series.
The index to the articles in this series is found here.
Well, we’re ready to go now. We have just to identify consecutive runs of 36 radar images, and bin up the rain/no-rain data appropriately for the 5 prediction windows.
We’ve got a simple script for that, get-training-set.py:
#! /usr/bin/python3
# Here we generate the training set candidates.
#
# We read the list of records made by prepare-true-vals.py from a
# file, and produce a list of candidates on stdout
#
# A training set candidate is a run of 6 sequence numbers representing
# the previous hour of historical data, while the following 30
# sequence numbers inform the rain/no-rain data for the five 1-hour
# blocks of future predictions.
#
# A training set candidate is available when there exists a set of 36
# consecutive sequence numbers. In that case, we generate a record
# like this:
#
# <FIRST_SEQ_NO> <HASH> <N_ROTS> <ROTNUM> <RAIN0_1> <HEAVY0_1> ...
#
# The first field is the starting sequence number in the run of 36.
#
# The second is the hash, as in prepare-true-vals.py, to ensure that
# we don't accidentally mix incompatible training data
#
# The third field is the number of rotations from which this is taken,
# or 0 if we're using unrotated data sets
#
# The fourth field is the rotation index. 0 for unrotated, up to 1
# less than N_ROTS
#
# The fifth field is the logical OR of the RAIN record for the 7th
# through 12th sequence numbers. The sixth is the logical OR of the
# HEAVY_RAIN record for the 7th through 12th sequence numbers.
#
# The following 8 fields are as above, for subsequence runs of 6
# sequence numbers.
import argparse
import rpreddtypes
parser = argparse.ArgumentParser(description='Find training candidates.',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('truevalfile', type=str, metavar='truevalfile',
help='Filename to process')
parser.add_argument('--override-centre', type=list, dest='centre',
default=[240,239], help='Set a new location for '
'the pixel coordinates of the radar station')
parser.add_argument('--override-sensitive-region', type=list,
dest='sensitive',
default=[[264,204], [264,205], [265,204], [265,205]],
help='Set a new list of sensitive pixels')
parser.add_argument('--rotations', type=int, dest='rotations',
default=0, help='Number of synthetic data points '
'to create (via rotation) for each input data point')
parser.add_argument('--heavy-rain-index', type=int, dest='heavy',
default=3, help='Lowest index in the colour table '
'that indicates heavy rain, where 1 is the '
'lightest rain.')
args = parser.parse_args()
hashval = rpreddtypes.genhash(args.centre, args.sensitive, args.heavy)
seqnoList = []
parsedData = {}
nRots = -1
skipRotations = False
with open(args.truevalfile, 'r') as ifile:
for record in ifile:
fields = record.split()
if fields[2] != hashval:
continue
# Check for inconsistent number of rotations
if nRots != -1 and nRots != int(fields[3]):
skipRotations = True
nRots = int(fields[3])
seqnoList.append(int(fields[0]))
value = [ int(fields[3]) ]
value[1:1] = list(map(int, fields[4:]))
parsedData[int(fields[0])] = value
seqnoList.sort()
if skipRotations:
nRots = 0
# Now, we've loaded sequence numbers into a list, and indexed a dict
# against them to record number of rotations and rain data.
# Find runs of 36.
idx = 0
while idx < len(seqnoList) - 36:
candSeqNo = seqnoList[idx]
offset = 1
invalid = False
while not invalid and offset < 36:
if seqnoList[idx + offset] != seqnoList[idx + offset - 1] + 1:
invalid = True
idx = idx + offset
offset += 1
if invalid:
continue
for rot in range(nRots + 1):
record = '{0} {1} {2} {3} '.format(candSeqNo, hashval, nRots, rot)
binnedValues = [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
for timeInterval in range(5):
for snapshot in range(6):
oneRec = parsedData[candSeqNo + 6 + timeInterval * 6 + snapshot]
if oneRec[1 + rot * 2] == 1:
binnedValues[timeInterval * 2] = 1
if oneRec[1 + rot * 2 + 1] == 1:
binnedValues[timeInterval * 2 + 1] = 1
print(record, *binnedValues, sep = ' ')
idx += 1
We consider each training record to be 36 radar images. The first six are the historical data, they’re the inputs to the neural network. The following 30 images form the ‘true’ results, the actual occurence or not of rain in the five one-hour long bins following the historical interval.
This script produces records consisting of the first sequence number in the run of 36, the hash (as before, to prevent the accidental mixture of incompatible data), two fields to identify the rotation of the true prediction values, and a set of 10 zeros or ones. The first pair of numbers are 1 if there is rain/heavy-rain in the 6 records immediately following the historical data, indicating the first hour of the prediction. The next pair of numbers is the same for the second hour of prediction, and so on.
For now, I’ve chosen not to enable rotations on the data while I work out the neural network.
Now, in my summer 2015 data, I’ve got 10518 candidate records, of which 3740 predict at least some rain. That’s kind of interesting, it suggests that, on average in 2015, at any given moment we were about 36% likely to have rain some time in the next 5 hours.
Now, 36% isn’t actually a bad training fraction. We could probably afford to cut down the no-rain cases by half, to balance the data, assuming we’re not going for an auto-encoder trained only against the no-rain case.
We won’t be using an auto-encoder. The fact that we have close to a million input pixels per training element makes that quite impractical for this project.
So, how can we thin our input set to remove half of the no-rain entries? Well, clear skies leading to clear skies seems to be fairly uninteresting, and we don’t think we need to train our network against that. How about, for each candidate with no rain predicted over the next 5 hours, we count up the total rain intensity in the historical run of 6 radar images. That is, the sum of the pixel values, so heavy rain might count 6 on a pixel, and light rain only 2. Add these up over the historical interval, and the smallest aggregated numbers are the ones that show the least precipitation over that hour on the radar images. We could then drop the bottom half, with the least precipitation, but… there’s a danger in that. We would, in effect, be failing to train the network on the clearest sky cases, forcing it to extrapolate to what is a fairly common input. The network might wind up handling that case badly, since it never saw training data in that domain. So, I’d suggest that we drop data preferentially on the bottom end, but not exclusively so. If we’re trying to delete half of the no-rain data, perhaps we start from the lowest precipitation images and keep every fifth one as we walk up the list. This way we still remove a lot of relatively uninteresting training data, but we keep enough of it in to ensure that the network isn’t unaware of this case.
In the next brief posting, I’ll write a script to do this data thinning. Then, we’ll be able to get to the actual construction of the neural network.
UPDATE #1 (2019-08-23): Included a link to an index of articles in this series.
The index to the articles in this series is found here.
We’re almost ready to feed out data into the neural network. We’ve generated intermediate binary data files for our .gif files, now we need a way to find a set of at least 36 consecutive timestamped files, and an indication of whether a particular binary data file shows rain, and whether that rain is heavy. We also will want to mark the rain/no-rain condition for our synthetic rotated data, assuming that our local geography makes rotated data plausible.
We’re going to make a set of records, one to a line, that contain everything the neural network training script will need. A script will output these to stdout, so that it can easily be appended to our list as our data grows.
My data was collected from June to September of 2015, and I restarted the collector one week ago when I decided to take up this project, so I’ve got some data from August of 2019. My filenames all have UTC date and time specifiers. Always do that. You don’t want to have to care about standard/savings time switches in your filenames.
I’ll declare the UTC time 2015-01-01T00:00:00Z to be my epoch. That’s midnight on January 1, 2015, UTC. I know that data is available every 10 minutes from the radar station, so my sequence number will simply be the number of 10 minute intervals that have passed between that epoch and the timestamp of this particular file. This sequence number is the first field in the record.
I will also need a reference to the intermediate binary file itself. That will be the second field in the record.
The third field in the record is a hash of the centre of the radar image, the sensitive pixels, and the threshold that defines ‘heavy’ rain. This is to verify that we don’t accidentally mix incompatible data in our training set.
The next field in the record is the number of rotations we are calculating. 0 indicates no rotations, and 3 indicates we’ll have 4 total orientations, the original one plus three 90 degree rotations.
Following this, we have a pair of integers. 0/1 indicates no/any rain in the first field, and indicates no/any heavy rain in the second field.
If we have rotations, then each rotation has two more fields just like the ones above, indicating presence or absence of rain, and whether it’s heavy rain.
I’ve added a new function to rpreddtypes.py:
def genhash(centre, senseList, heavyThreshold, seed = 0xabcddcba):
"""
Returns a string, a hash derived from MD5 of the inputs
"""
hasher = hashlib.md5()
hasher.update('{0:0>8x}'.format(seed).encode('ascii'))
hasher.update('{0:0>8x}{1:0>8x}'
.format(centre[0], centre[1])
.encode('ascii'))
for tuple in senseList:
hasher.update('{0:0>8x}{1:0>8x}'
.format(tuple[0], tuple[1])
.encode('ascii'))
hasher.update('{0:0>8x}'.format(heavyThreshold).encode('ascii'))
return hasher.digest().hex()[0:8]
This generates the hash I’ll need to verify in the training code.
Now, we’re ready for the script itself. This is prepare-true-vals.py:
#! /usr/bin/python3
# This script will parse one or more of the intermediate binary files
# for the rain predictor and will produce a record on stdout. A
# record consists of one line:
# <SEQ_NO> <FULL_PATH> <HASH> <N_ROTS> <RAIN_0> <HEAVY_RAIN_0> ...
# The SEQ_NO is a sequence number, the number of .gif files that ought
# to have been produced between 2015-01-01T00:00:00Z and now, assuming
# constant 10 minute intervals. That's because we need an unbroken
# sequence of 6 hours of data for a training element, so checking for
# contiguous blocks of sequence numbers will be a quick determinant
# FULL_PATH is the pathname of the intermediate binary file.
# HASH is a 32-bit integer computed from the pixel coordinates of the
# radar station and of the rain-sensing pixels. Represented as a
# 32-bit hex value with a leading 0x, it is there so we can
# distinguish training records for different areas of interest, if we
# should ever expand to that.
# N_ROTS is the number of rotations in this data. '0' indicates only
# the unrotated set is present. For numbers greater than 0, the
# rotations are assumed to be evenly divided over the circle, and
# count COUNTER-CLOCKWISE from the unrotated entry.
# RAIN_0 HEAVY_RAIN_0 is 0 or 1, 1 if there is any rain/heavy-rain in
# any of the rain-sensing pixels for this intermediate binary file, 0
# otherwise. The _0 suffix indicates the unrotated set. If rotated
# data is present, there will be pairs of records for each such
# rotation.
# IMPORTANT NOTE:
#
# the rotations of the rain-sensing region are counter-clockwise
# rotations. That's because we're going to consider the rotations of
# the input set to be clockwise rotations, and rotating the rain
# clockwise means we have to rotate the sensing pixels
# counter-clockwise to get correct results.
# Also, remember we're using the same pixel numbering scheme as in the
# .gif file, the first index counts across a row, the second counts
# down rows. This is a left-handed coordinate system, adjust the
# trigonometry appropriately.
import argparse
import sys
import os
import rpreddtypes
import numpy as np
import re
import datetime
import math
phantomRainRadius = 20
phantomRainFrac = 0.5
epoch = datetime.datetime(year=2015, month = 1, day = 1,
hour = 0, minute = 0)
def rotate_pixel_CCW (pixel, centre, nDiv, rotNum):
"""
Rotates the pixel counter-clockwise around the centre by rotNum *
2 pi / nDiv. Special case treatment for nDiv = 2 or 4, since
D_2 and D_4 symmetry groups are contained within the square grid.
rotNum counts up from 1, so must not exceed nRots
"""
if nDiv == 1:
return pixel.copy()
if nDiv <= 0 or rotNum <= 0 or rotNum > nDiv:
print('Invalid invocation of rotate_pixel_CCW. '
'nDiv={0} and rotNum={1}'.format(nDiv, rotNum))
sys.exit(1)
delta = pixel.copy()
delta[0] -= centre[0]
delta[1] -= centre[1]
rval = pixel.copy()
if nDiv == 2 or ( nDiv == 4 and rotNum == 2):
rval[0] = centre[0] - delta[0]
rval[1] = centre[1] - delta[1]
return rval
if nDiv == 4:
if rotNum == 1:
rval[0] = centre[0] + delta[1]
rval[1] = centre[1] - delta[0]
return rval
if rotNum == 3:
rval[0] = centre[0] - delta[1]
rval[1] = centre[1] + delta[0]
return rval
# If we get here, it's a rotation not covered by the symmetry of
# the grid. Note that we lose the 1-1 mapping guarantee now.
# It's possible for two different input pixels to map to the same
# output pixel.
theta = (np.pi * 2 / nDiv) * rotNum
sinT = np.sin(theta)
cosT = np.cos(theta)
# left-handed rotation matrix
rmat = np.array(((c, s), (-s, c)))
deltavec = np.array(delta)
deltavec = rmat.dot(deltavec)
rval[0] = centre[0] + deltavec[0]
rval[1] = centre[1] + deltavec[1]
return rval
def computeSequenceNumber(filename):
"""
Returns a sequence number, or -1 on error
"""
# My names are in the form "<dirs>/radar_YYYY_MM_DD_HH_MM.gif
# I will search for the numeric sub-sequence, and ignore the rest
match = re.search(r'.*([0-9]{4})_([0-9]{2})_([0-9]{2})'
'_([0-9]{2})_([0-9]{2}).*', filename)
if not match:
return -1
year = int(match.group(1))
month = int(match.group(2))
day = int(match.group(3))
hour = int(match.group(4))
minute = int(match.group(5))
mytime = datetime.datetime(year = year, month = month, day = day,
hour = hour, minute = minute)
delta = mytime - epoch
return int(delta.total_seconds() / 600)
def rainPresent(binReader, centre, sensitivePixels, heavyVal):
"""
Returns a list of 2 integer elements. The first indicates any
rain at all in any of the sensitive pixels. The second indicates
rain above the threshold intensity for heavy rain.
"""
maxSeen = 0
anyRain = 0
heavyRain = 0
checkPhantom = True
xoffset = binReader.xoffset
yoffset = binReader.yoffset
offset = [xoffset, yoffset]
dataWidth = binReader.width
dataHeight = binReader.height
data = binReader.getNumpyArray()
for pixel in sensitivePixels:
pval = data[pixel[0] - xoffset][pixel[1] - yoffset]
if pval > 0:
anyRain = 1
if pval > 1:
checkPhantom = False
if pval >= maxSeen:
maxSeen = pval
if maxSeen >= heavyVal:
heavyRain = 1
return [ 1, 1 ]
if not anyRain:
return [ 0, 0 ]
if not checkPhantom:
return [ anyRain, heavyRain ]
# Have to check for phantom rain. If all pixels within
# 'phantomRainRadius' of the centre are 0 or 1, and the fraction
# of elements that are 1 is less than 'phantomRainFrac', then we
# declare the rain to be an instrumental artefact
nPixels = 0
nSetPixels = 0
for probeY in range(-phantomRainRadius, phantomRainRadius):
deltaX = int(math.sqrt(phantomRainRadius ** 2 - probeY ** 2))
for probeX in range(-deltaX, deltaX):
probePt = [ centre[0] + probeX - offset[0],
centre[1] + probeY - offset[1]]
if ( probePt[0] < 0 or probePt[0] >= dataWidth
or probePt[1] < 0 or probePt[1] >= dataHeight ):
continue
nPixels += 1
pixelVal = data[probePt[0]][probePt[1]]
# If we've got a pixel larger than 1, no phantom rain
if pixelVal > 1:
return [anyRain, heavyRain]
if pixelVal == 1:
nSetPixels += 1
if nSetPixels >= nPixels * phantomRainFrac:
return [ anyRain, heavyRain ]
else:
return [ 0, 0 ]
## Main execution begins here
parser = argparse.ArgumentParser(description='Build training sequence.',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('ifilenames', type=str, metavar='filename',
nargs='+', help='Filenames to process')
parser.add_argument('--override-centre', type=list, dest='centre',
default=[240,239], help='Set a new location for '
'the pixel coordinates of the radar station')
parser.add_argument('--override-sensitive-region', type=list,
dest='sensitive',
default=[[264,204], [264,205], [265,204], [265,205]],
help='Set a new list of sensitive pixels')
parser.add_argument('--rotations', type=int, dest='rotations',
default=0, help='Number of synthetic data points '
'to create (via rotation) for each input data point')
parser.add_argument('--heavy-rain-index', type=int, dest='heavy',
default=3, help='Lowest index in the colour table '
'that indicates heavy rain, where 1 is the '
'lightest rain.')
args = parser.parse_args()
hashString = rpreddtypes.genhash(args.centre, args.sensitive, args.heavy)
for inputfile in args.ifilenames:
rpReader = rpreddtypes.RpBinReader()
rpReader.read(inputfile)
record = '{0} {1} {2} {3}'.format(computeSequenceNumber(inputfile),
os.path.abspath(inputfile),
rpreddtypes.genhash(args.centre,
args.sensitive,
args.heavy),
args.rotations)
truevals = rainPresent(rpReader, args.centre, args.sensitive, args.heavy)
record = '{0} {1} {2}'.format(record, truevals[0], truevals[1])
for rot in range(args.rotations):
sense2 = args.sensitive.copy()
for i in range(len(sense2)):
sense2[i] = rotate_pixel_CCW(sense2[i], args.centre,
args.rotations + 1, rot + 1)
truevals = rainPresent(rpReader, args.centre, sense2, args.heavy)
record = '{0} {1} {2}'.format(record, truevals[0], truevals[1])
print (record)
So, we run that script on all of the input files I have so far, and see what we find. Scanning over my files from 2015, I have 10921 radar images. The analysis process determines that of these images, 667 indicate rain in Ottawa, and of those, 156 are heavy rain. So, we have a 6% event rate for any rain, and 1.5% for heavy rain. We’re going to have to keep this imbalance in mind when we design our neural network training set, as training works better with balanced data. I could easily design a network with a 94% accurate prediction rate, by training it to say “no rain” all the time, but I would miss the events I really care about.
Now, note that the problem isn’t to decide whether it’s raining in Ottawa, we already know that. We want to train the network to predict rain over the next 5 hours. That means our training data is not individual images, but consecutive runs of 36 images. The first 6 images in each run represent the data that will be presented to the network in order for it to form its prediction, the last hour of radar data. The next 30 images will be used to form the true data, whether rain actually fell in each block of 6 images and whether it was heavy rain.
So, our next post will generate the candidates for a training set. There, we’ll check the rare event statistics again and decide how we’re going to handle the training. Possibilities include trimming the no-rain set so that rain and no-rain entries are roughly equally represented in the training set, making multiple copies of the rain set for the same goal, producing an auto-encoder trained on the no-rain set, or maybe some other approach.
Of course, you’ll also start to wonder how we’re handling the time sequence. We’ll get to that soon.
UPDATE #1 (2019-08-23): Included a link to an index page of articles in this series.
The index to the articles in this series is found here.
So, we’re about ready for our next step. Converting those .gif files from the radar station into files holding no extraneous information, just precipitation data. So, that colour bar on the right can go, as can all the background. We want to encode those pixels so that any non-rain pixel has a value of 0, and rain pixels have numeric values that increase as the intensity of rain increases.
So, in earlier postings we created a background image. Now, for each radar image, we compare the background to the new image. Where pixels differ, if the colour in the new image can be found in a reference table of colours to rain intensities, then we record the appropriate ordinal of the table entry in the file.
I’ll record the results in a binary data file of my own. Because I’ll have to read these files from multiple scripts, it makes sense to create classes to manipulate them, and to design a file format that can verify that we’re not reading some random file not of my creation.
Here, then, is the manipulation package, called rpreddtypes.py:
#! /usr/bin/python3
import numpy as np
import gzip
# First, classes to manipulate the intermediate binary file.
#
# Format:
# RAIN PREDICTOR BIN FILE\n
# VERSION 1\n
# WIDTH NNN\n
# HEIGHT NNN\n
# XOFFSET NNN\n
# YOFFSET NNN\n
# <Binary blob of byte values>
class RpBinFileReadError(Exception):
def __init__(self, message):
self.message = message
class RpBinCommon:
HEADER_KEY = 'RAIN PREDICTOR BIN FILE'
VERSION_KEY = 'VERSION'
WIDTH_KEY = 'WIDTH'
HEIGHT_KEY = 'HEIGHT'
XOFFSET_KEY = 'XOFFSET'
YOFFSET_KEY = 'YOFFSET'
class RpBinReader(RpBinCommon):
"""
Reader for intermediate binary data type
"""
def __init__ (self,):
self.version = 0
self.buffer = b''
self.blen = 0
self.width = 0
self.height = 0
self.xoffset = 0
self.yoffset = 0
def read(self, filename):
with open(filename, 'rb') as istream:
try:
istream = open(filename, 'rb')
except OSError as ex:
raise RpBinFileReadError(ex.strerror)
header = istream.readline().rstrip().decode('ascii')
if header != self.HEADER_KEY:
raise RpBinFileReadError('File {0} is not a valid '
'file'.format(filename))
vstr, vnum = (istream.readline().rstrip()
.decode('ascii').split(" "))
if vstr != self.VERSION_KEY:
raise RpBinFileReadError('File {0} is not a valid '
'file'.format(filename))
if vnum != '1':
raise RpBinFileReadError('File {0} is version {1}'
'which is not supported'
'by this code'.format(filename,
vnum))
width, self.width = (istream.readline().rstrip()
.decode('ascii').split(" "))
self.width = int(self.width)
if width != self.WIDTH_KEY or self.width < 0:
raise RpBinFileReadError('File {0} is not a valid '
'file'.format(filename))
height, self.height = (istream.readline().rstrip()
.decode('ascii').split(" "))
self.height = int(self.height)
if width != self.WIDTH_KEY or self.height < 0:
raise RpBinFileReadError('File {0} is not a valid '
'file'.format(filename))
xoffset, self.xoffset = (istream.readline().rstrip()
.decode('ascii').split(" "))
self.xoffset = int(self.xoffset)
if xoffset != self.XOFFSET_KEY or self.xoffset < 0:
raise RpBinFileReadError('File {0} is not a valid '
'file'.format(filename))
yoffset, self.yoffset = (istream.readline().rstrip()
.decode('ascii').split(" "))
self.yoffset = int(self.yoffset)
if yoffset != self.YOFFSET_KEY or self.yoffset < 0:
raise RpBinFileReadError('File {0} is not a valid '
'file'.format(filename))
btmp = istream.read()
self.buffer = gzip.decompress(btmp)
self.blen = self.width * self.height
if self.blen != len(self.buffer):
raise RpBinFileReadError('File {0} is '
'corrupted'.format(filename))
def getVersion():
return self.version
def getWidth():
return self.width
def getHeight():
return self.height
def getXOffset():
return self.xoffset
def getYOffset():
return self.yoffset
def get1Dbuffer():
return self.buffer
def getNumpyArray():
array = np.arange(self.width * self.height, dtype=bool)
for i in range(self.width * self.height):
array[i] = self.buffer[i]
return array.reshape(self.width, self.height)
class RpBinWriter(RpBinCommon):
def __init__(self):
pass
def write(self, filename, width, height, xoffset, yoffset, values):
with open(filename, 'wb') as ofile:
ofile.write('{0}\n'.format(self.HEADER_KEY)
.encode('ascii'))
ofile.write('{0} {1}\n'.format(self.VERSION_KEY, 1)
.encode('ascii'))
ofile.write('{0} {1}\n'.format(self.WIDTH_KEY, width)
.encode('ascii'))
ofile.write('{0} {1}\n'.format(self.HEIGHT_KEY, height)
.encode('ascii'))
ofile.write('{0} {1}\n'.format(self.XOFFSET_KEY, xoffset)
.encode('ascii'))
ofile.write('{0} {1}\n'.format(self.YOFFSET_KEY, yoffset)
.encode('ascii'))
ofile.write(gzip.compress(bytearray(values)))
This will be used by our script that generates binary training data files from .gif files. That’s this one, make-rain-inputs.py:
#! /usr/bin/python3
# This script will take .gif files downloaded from the radar station
# and convert them to a simpler format for eventual use. It will
# contain only information about precipitation or its absence, in a
# set of integer steps.
import argparse
import sys
import gif
import rpreddtypes
parser = argparse.ArgumentParser(description='Extract '
'precipitation data.')
parser.add_argument('ifilenames', type=str,
metavar='filename', nargs='+',
help='Filenames to process')
parser.add_argument('--baseline', type=str,
dest='baseline',
help='The baseline .gif file')
parser.add_argument('--width', type=int, dest='owidth',
default=-1,
help='The width of the sub-rectangle '
'that is to be output')
parser.add_argument('--height', type=int, dest='oheight',
default=-1,
help='The height of the sub-rectangle '
'that is to be output')
parser.add_argument('--top-left-x', type=int, dest='offsetx',
default=0,
help='The x-value of the upper left '
'of the sub-rectangle that is to be output')
parser.add_argument('--top-left-y', type=int, dest='offsety',
default=0,
help='The y-value of the upper left '
'of the sub-rectangle that is to be output')
parser.add_argument('--override-intensities', type=list,
dest='intensities',
default=[0x99ccff, 0x0099ff, 0x00ff66,
0x00cc00, 0x009900, 0x006600,
0xffff33, 0xffcc00, 0xff9900,
0xff6600, 0xff0000, 0xff0299,
0x9933cc, 0x660099],
help='Override the colour codes for '
'intensities')
parser.add_argument('--verbose', type=bool, dest='verbose',
default = False,
help='Extra output during processing')
args = parser.parse_args()
if not args.baseline:
print ('A baseline comparison file must be supplied '
'with the --baseline argument')
sys.exit(1)
baselineReader = gif.Reader()
bfile = open(args.baseline, 'rb')
baselineReader.feed(bfile.read())
bfile.close()
if ( not baselineReader.is_complete()
or not baselineReader.has_screen_descriptor() ):
print ('Failed to parse {0} as a '
'.gif file'.format(args.baseline))
sys.exit(1)
baselineBuffer = baselineReader.blocks[0].get_pixels()
baselineColours = baselineReader.color_table
baselineWidth = baselineReader.width
baselineHeight = baselineReader.height
newwidth = baselineWidth
if args.owidth != -1:
newwidth = args.owidth
newheight = baselineHeight
if args.oheight != -1:
newheight = args.oheight
xoffset = args.offsetx
yoffset = args.offsety
for ifile in args.ifilenames:
convertReader = gif.Reader()
cfile = open(ifile, 'rb')
convertReader.feed(cfile.read())
cfile.close()
if ( not convertReader.is_complete()
or not convertReader.has_screen_descriptor() ):
print ('Failed to parse {0} as a '
'.gif file'.format(ifile))
sys.exit(1)
if ( len(convertReader.blocks) != 2
or not isinstance(convertReader.blocks[0], gif.Image)
or not isinstance(convertReader.blocks[1], gif.Trailer)):
print ('While processing file: {}'.format(ifile))
print ('The code only accepts input files with a single block of '
'type Image followed by one of type Trailer. This '
'constraint has not been met, the code will have to be '
'changed to handle the more complicated case.')
sys.exit(1)
convertBuffer = convertReader.blocks[0].get_pixels()
convertColours = convertReader.color_table
convertWidth = convertReader.width
convertHeight = convertReader.height
if baselineWidth != convertWidth or baselineHeight != convertHeight:
print('The baseline file ({0}) and the file to convert {1} '
'have incompatible dimensions'.format(args.baseline,
ifile))
sys.exit(1)
output_block = []
for pixel in range(len(baselineBuffer)):
row = pixel // baselineWidth
col = pixel % baselineWidth
if row < yoffset:
continue
if row >= yoffset + newheight:
break
if col < xoffset or col >= xoffset + newwidth:
continue
if pixel >= len(convertBuffer):
output_block.append(0)
continue
btuple = baselineColours[baselineBuffer[pixel]]
ctuple = convertColours[convertBuffer[pixel]]
if btuple == ctuple:
output_block.append(0)
else:
code = ( ctuple[0] * 256 * 256
+ ctuple[1] * 256
+ ctuple[2] )
appendval = 0
for i in range(len(args.intensities)):
if code == args.intensities[i]:
appendval = i+1
break
output_block.append(appendval)
newfilename = ifile + '.bin'
writer = rpreddtypes.RpBinWriter()
writer.write(newfilename, newwidth, newheight, xoffset, yoffset,
output_block)
if (args.verbose):
print('Wrote output file: {0}'.format(newfilename))
In the next posting we’ll need a script to generate the true values. That is, for each file, whether it indicates rain in Ottawa, and whether that rain is heavy. We’ll also want to attach a sequence number to each file, allowing us to know when we have continuous runs of data that we need to make a single training entry.
Update #1: Fixed a bug that resulted in rainfall in the lowest intensity bin not being recorded.
UPDATE #2 (2019-08-23): Included a link to an index page of articles in this series.
The index to the articles in this series is found here.
So, I’ve got a baseline image I can use to extract active precipitation data from the government website. Now, can we just throw everything into a neural network?
The temptation is there, let the network do everything, but we have to understand our problem well enough to make sure we are using the network well. After all, neural networks turn into big black boxes, you can’t easily pull out weights one at a time and examine them to see if they look right.
Well, our time series of data for rainfall is going to have clouds moving more or less in a straight line and at a speed in the tens of kilometres per hour. Most of these events will move from roughly WSW towards ENE, but we should expect that rain might blow in from any direction. The problem is that my training set almost certainly doesn’t have any data for rain blowing in from the East. If I train with the data I have, the neural network will decide that rainfall to the East of Ottawa can never cause rainfall in Ottawa, and so input weights for pixels on that side will be zero or small. Then, when rain really does come in from there, the neural network will be surprised, and I will get wet.
It might be nice, then, to synthesize data for rain coming from the East. The most obvious way to do this is to rotate the incoming data. Note, though, that I don’t want the position of Ottawa itself to change on the plot, and the radar dish is not in Ottawa, but some distance to the South-West, in Franktown. Now, by rotating the input data we are assuming that weather patterns that approach from the East are very similar to those that approach from the West. They display a similar lack of high deflections, have similar speeds of approach, and that the unconsidered causal agents responsible for the weather (such as fronts, temperature trends, moisture loss, etc.) can be treated as symmetrical. This assumption would probably not be true for a place like Hamilton, where lake effect snows mean that precipitation to the East is qualitatively different from that to the West, or Vancouver, with a huge ocean to the West and snow-covered mountains to the East. These places don’t demonstrate the degree of rotational symmetry that we consider important for such a simple data synthesis method. Ottawa, however, far from lakes and in a large plain, with only relatively low hills in the vicinity, doesn’t have any obvious external asymmetries aside from that imposed by the prevailing winds.
If you look at the map in part 1 of this series, you’ll see that this data rotation approach on the Franktown radar station data wouldn’t work very well at all for rain in Montreal, as it is near the East edge of the imaging area, so we don’t actually have much data for rain inbound from East of Montreal. For Ottawa, though, we might be able to manage. Montreal has its own McGill radar station, so we wouldn’t be using Franktown data for Montreal in any case.
Rotations are a bit tricky on square data. We can easily rotate by steps of 90 degrees, because those operations are part of the symmetry group of the square (D_4 for all you group theory enthusiasts out there). Outside of those simple rotations, issues arise with floating-point roundoff, voids, and many-to-one mappings. If we have two adjacent pixels with value ‘3’ in the unrotated input set, and these pixels, after rotation, project partially onto four different pixels, how are we going to assign values to those pixels? The ‘3’ indicates intensity, so we don’t want to smooth it out to 1.5 on each pixel, and we’re using discrete intensities rather than continuous, so it might be awkward to try to sum up contributions on pixels in the rotated dataset. For now, we will just use the three available 90 degree rotations, as they do not distort the data, and we’ll evaluate the system’s behaviour to see if smaller rotations are necessary for good predictions.
We think, because our radar image is a disc, and rain travels more or less in straight lines, that radial movement of rain will be important. That is, rain moving toward the radar station will influence the likelihood of rain in Ottawa. Also, we’re probably not too worried about the fine details of rain falling far away, but close to Ottawa we need some finer resolution. So, let’s cut up the space a bit like a dartboard. We’ll cut the disc into a certain number of equal-width wedges, and each wedge will be cut by arcs of fixed radius. We’ll adjust the parameters of these regions to suit our model later.
So, do we centre these regions on Ottawa, or on Franktown? I’m going to centre them on the radar facility itself, because that allows for the possibility that, some time down the road, we decide to set up a system that monitors rain in two different places. We can’t centre our regions of interest on both, to do that would be just to say we’re creating two completely independent neural networks. At least to begin with, then, we’ll centre our division of the disc on the radar facility in Franktown.
Why aren’t we using convolutional neural networks? Well, that’s something we’ll keep in mind for later, but they’re the sort of thing you would use to investigate the shape of rainfall patterns within a region, and, at least for now, we think rainfall prediction is not so strongly dependent on the fine-scale features of the rainfall intensities within a region of space. So, my inputs are going to be broken into these disjoint regions, and the first layer of our network will only consider values within these regions, not between them. This is called a modular neural network. A module of neurons that look only at pixels in their area of responsibility, and feed some outputs up to the next layer for more analysis. The higher layer(s) will be able to work with outputs from multiple modules. For now, I’m not going to say how many outputs each of these first-layer regions will produce. With only one output, the network would probably train itself to something like “fraction of pixels in the region which show rain”, but it’s likely that we need a bit more information than that, so we will keep in mind the possibility that these regions will each be allowed produce multiple outputs if we decide that’s necessary. Also, the region(s) immediately around Ottawa are special. In there, we probably are interested in the fine-scale details of rainfall amounts, so we’ll either want to make those regions quite small, or we’ll want to expose those pixels separately to the higher layer of the network. It’s something to keep in mind.
OK, so that’s a basic outline of our proposed neural network topology. What about training data? We need some outcomes to validate predictions.
We’ll pick four pixels near the middle of Ottawa, and look at the rainfall in those pixels. If any pixel shows any rainfall, our real outcomes will have that bit set. If at least one pixel shows heavy rain, our real outcomes will have that other bit set. Since our bits are binned into one hour predictions and we have 6 radar images per hour, we’ll say that any rain in any one of those six radar observations will result in the corresponding bits being set.
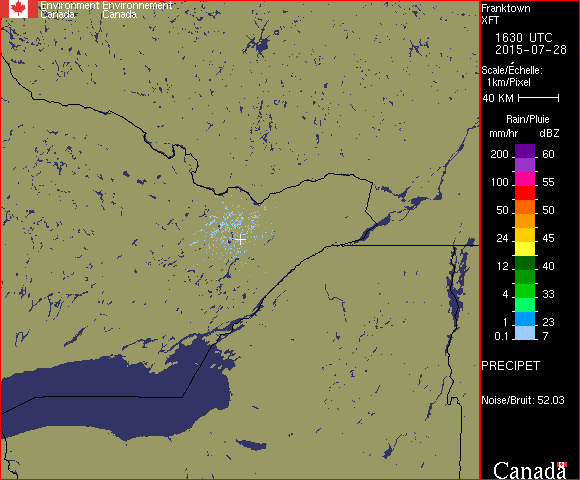
But, as always, there are complications. Recall in the previous article that there’s a close-range phantom rainfall observed when the skies are clear and it’s humid out. Ottawa lies within this region of phantom rainfall, which means that a naive extraction would conclude that it’s almost always raining over Ottawa on muggy days. Here’s an example of such phantom rainfall:
That rain near the white cross isn’t really there
What rule are we going to use to distinguish this phantom rainfall from real rain? Well, domain knowledge time again. These regions of phantom rainfall only appear as the lightest rainfall rate, and appear as scattered pixels rather than solid regions. In real light rainfall, we always see large areas of light rain, usually with heavier rain inside. So, that’s going to be our rule. If there are only light blue active pixels within, say, 20 pixels of the radar facility, and if the density of such pixels is less than 0.5, then we’ll say that the purported rain in Ottawa is, in fact, not there. We might have to tune this condition later, but this will make a starting point.
OK, so we’ve laid out a preliminary approach. We might discover after testing that we need to do things differently, but we now have a viable first attempt.
In our next posting, we’ll process the input data to make it suitable for feeding to the neural network.
UPDATE #1 (2019-08-23): Added a link to an index page of articles in this series.