The index to the articles in this series is found here.
I was going to show the impacts of a few different modifications, but the first one showed some interesting effects that are worth discussing up front.
Knowlegeable readers who have been watching the source code carefully might have wondered at the use of the SGD optimizer in conjunction with a recurrent neural network. For such a network, the RMSprop optimizer is generally a better choice. I had the SGD optimizer there as a good initial baseline for comparison. I trained my network with that optimizer, with no regularizers, to show what happens as we start to tweak the settings.
So, my first modification is to use the RMSprop optimizer. Running with the same data as we had for the SGD optimizer, we see something interesting. In first graph below, I plot the training loss and the validation loss for the SGD and RMSprop versions as we iterate through 400 epochs.
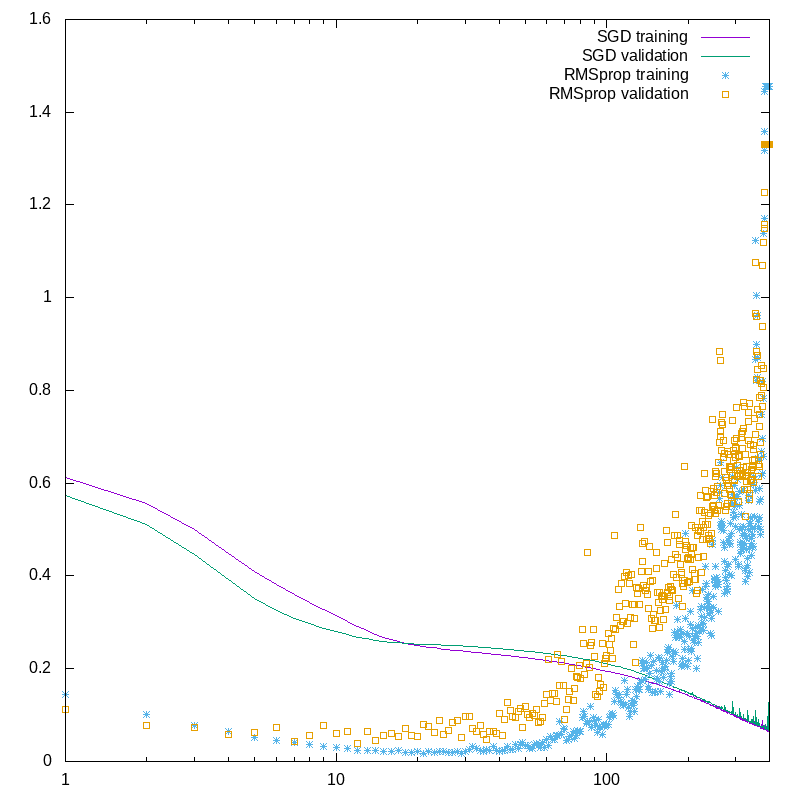
I’ve plotted the epoch number logarithmically to help show the detail in the early epochs.
First, look at the solid lines. The purple line is the training loss, the green line is the validation loss. They track together quite nicely, though there starts to be a bit of jittering of the validation loss at the higher epoch numbers.
The RMSprop values are the points. Note that even after one generation, the loss is dramatically better than for SGD. There are two things we see in this plot. First, that fairly early on, the validation loss becomes much worse than the training loss. Second, that the training loss gets very bad after a while. Here’s another plot, with a linear X axis, showing just these two traces:
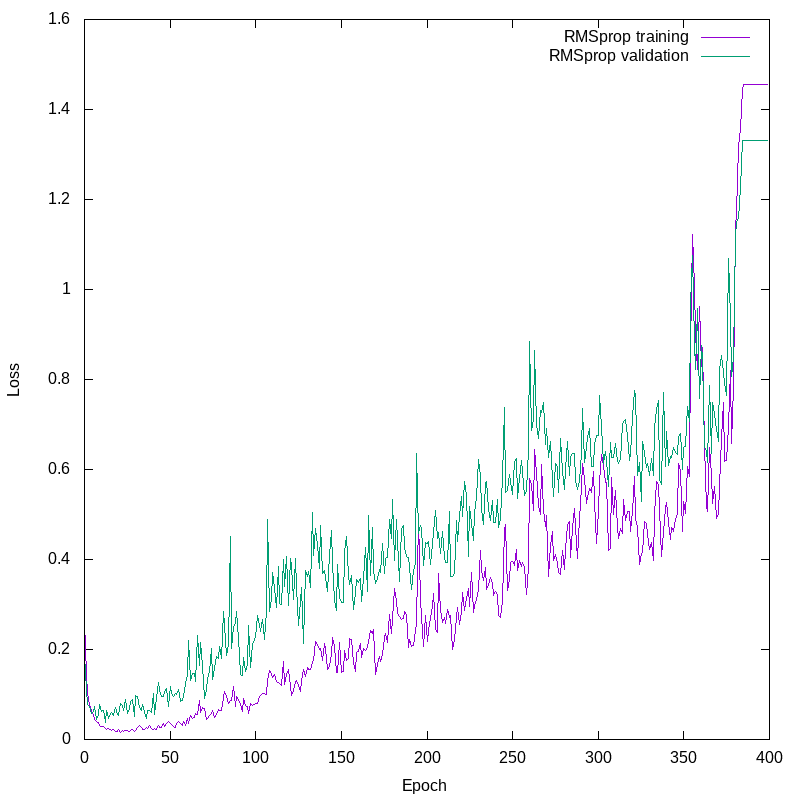
So, when the validation loss worsens even as the training loss improves, you have to think that we are probably overfitting the model. Overfitting is when the model becomes too finely tuned to the training data, and effectively becomes good at reproducing that specific dataset, rather than fitting to the trends that produced that dataset. The training and validation loss curves are also quite jittery (I avoid using the term “noisy”, as that has a precise statistical meaning). This overfitting doesn’t actually last long, because shortly afterward, the training falls apart.
The roughness of the loss curves can be traced back to the batch size. The fit() function in Keras still operates in batches. By default, it takes a batch of 32 inputs, runs them through the network, and generates a loss value. It then feeds this back into the network and tunes the weights. This process repeats with the next batch of 32 inputs, until the entire training set had been seen. Between epochs, the inputs are randomly shuffled, so the batches look different from one epoch to the next.
With its default settings, the RMSprop optimizer is quite aggressive. As each batch causes the network to be re-weighted, the variation between batches causes the weights to swing quite wildly. Just increasing the batch size reduces some of that early misbehaviour, because as the batches become larger they become statistically more alike, so outlier batches are less likely to appear and push the weights too strongly. In the case of my network here, with these default settings, we appear to have found a region of amplifying oscillations. Remember that loss is a measure of the amplitude of the departure of our model’s predictions from the true values. The oscillations in the weights are manifested as generally increasing loss values.
So, I said that the small batches, in conjunction with the aggressive weight tuning, were causing the oscillations. To demonstrate this, I re-ran the training, but using a batch_size of 256. Nothing else was changed. I plot the results here. This time I had to use a log scale in Y, just to be able to show the details of the differences, because of how far apart the loss curves are.
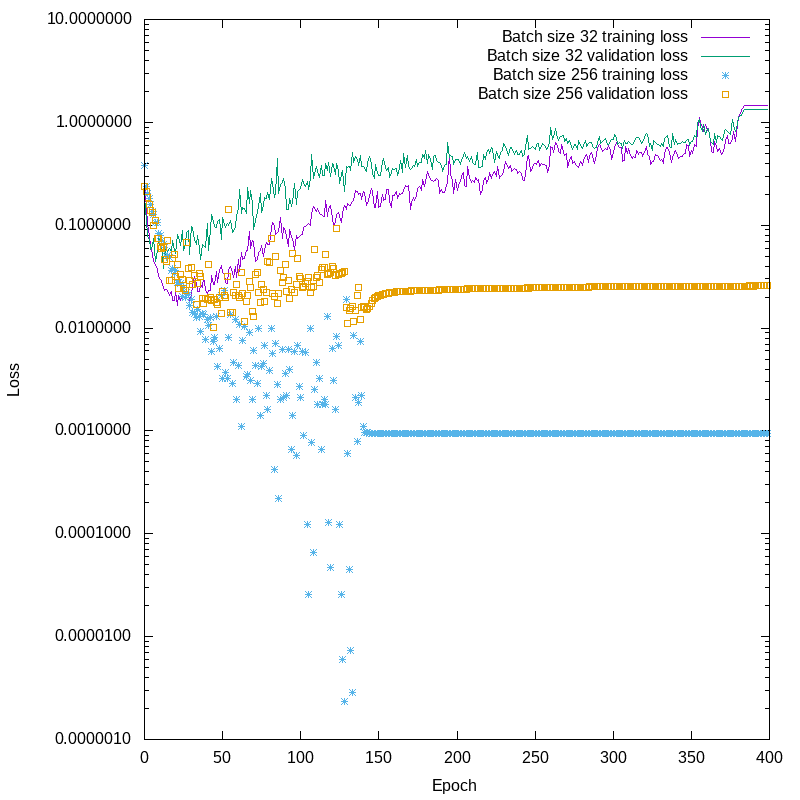
You can see that the amplifying oscillations have disappeared. Validation loss is still more than 10 times training loss with the larger batch size, so we have to worry about overfitting, but you can see that just before the training effectively stopped around epoch 170, the validation loss wasn’t monotonically increasing. The difference between the two losses might be purely statistical, due to differences between the training and validation datasets. There isn’t a clear fingerprint of overfitting.
Note at this point that we still haven’t started applying any regularizations. Those will come later.
OK, now you wonder if it might not be better to tune the learning rate than the batch size. There’s room for both approaches. For this particular project, a batch size of 32 really is too small, I’m training somewhat sparse binary data, so you want your batches large enough that they have a good chance of being representative, particularly when the training is as assertive as it is here with this optimizer.
So, what about the learning rate? The default value for the RMSprop learning rate in Keras is lr=0.001. For the next test, I reset the batch size to its default value of 32, and set the learning rate to 0.0001, reducing it tenfold. The following plot shows the difference between default learning rate and large batch size and lower learning rate with default batch size.
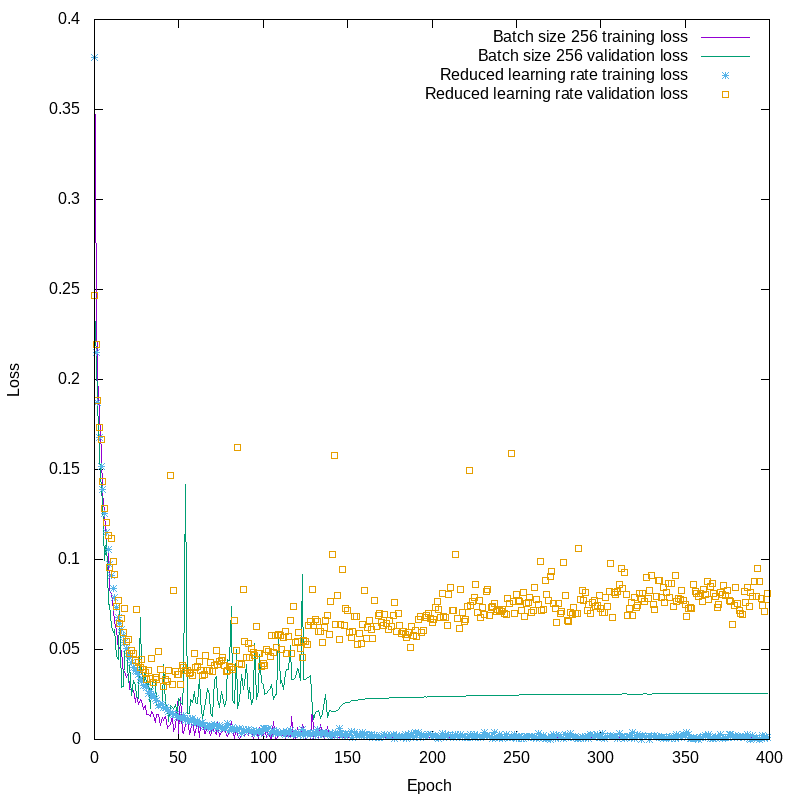
The training loss for the smaller learning rate looks, in this plot, to be quite similar to the larger batch size results. In fact, there’s a significant difference. Looking only at the training losses for epochs 200 and up, we see this:
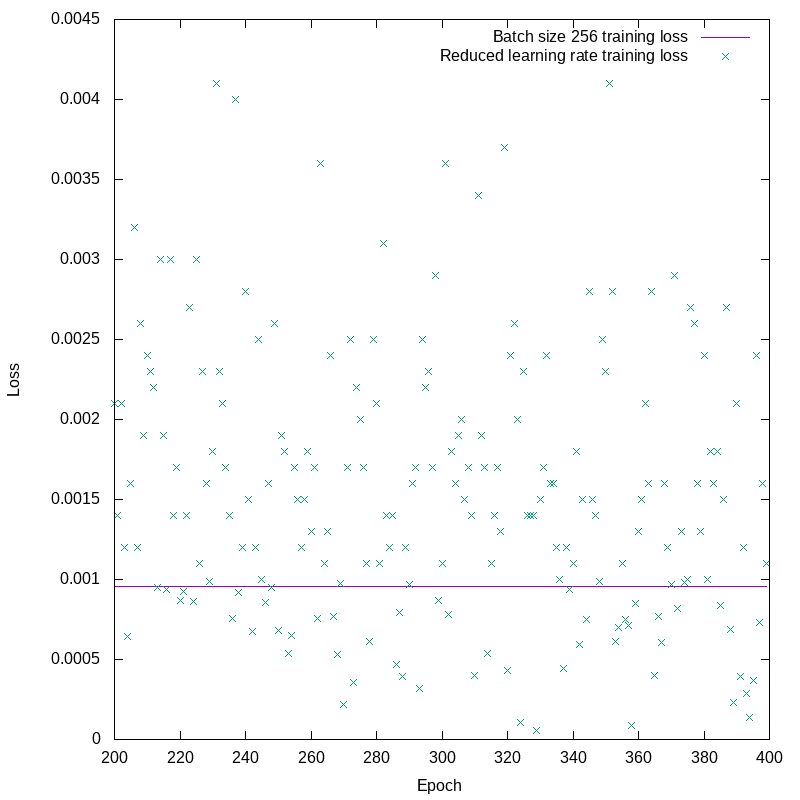
The training loss, while relatively small, is still oscillating all over the place. The smaller learning rate has succeeded in suppressing the runaway oscillations, but it hasn’t changed the fact that there are oscillations. You’ll also notice in figure 4 that the training loss looks smooth on that scale, but the validation loss is all over the place. We’ve hit one of the issues I mentioned early on, unbalanced weights leading to undesirable sensitivity to the inputs. This is a kind of overfitting, and it’s what we plan to address when we finally reach the topic of regularization. In the mean time, though, we have concluded that the RMSprop optimizer really needs higher batch sizes when running on this particular project.